A-double-flat note
The Solution below shows the position of note A-double-flat on the piano, treble clef and bass clef.
The Lesson steps then describe the note characteristics and relationship with the notes around it, and also lists which scales the note is in.
For a quick summary of this topic, have a look at Note name.
| Key | C | C# | Db | D | D# | Eb | E | E# | Fb | F | F# | Gb | G | G# | Ab | A | A# | Bb | B | B# | Cb |
|---|
Solution
1. A-double-flat note
Abb is a white key on the piano.
Another name for Abb is G, which has the same note pitch / sound, which means that the two note names are enharmonic to each other.
It is called double-flat because it is 2 half-tone(s) / semitone(s) down from the white note after which is is named - note A.
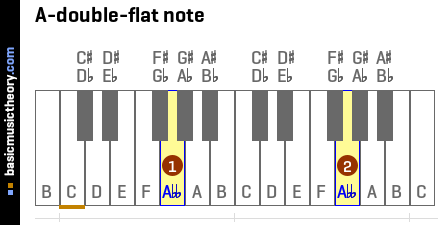
Middle C (midi note 60) is shown with an orange line under the 2nd note on the piano diagram.
These note names are shown below on the treble clef followed by the bass clef.


| Bass Clef: | Midi | MP3 | Treble Clef: | Midi | MP3 |
Lesson steps
1. Piano key note names
The white keys are named using the alphabetic letters A, B, C, D, E, F, and G, which is a pattern that repeats up the piano keyboard.
Every white or black key could have a flat(b) or sharp(#) accidental name, depending on how that note is used. In a later step, if sharp or flat notes are used, the exact accidental names will be chosen.
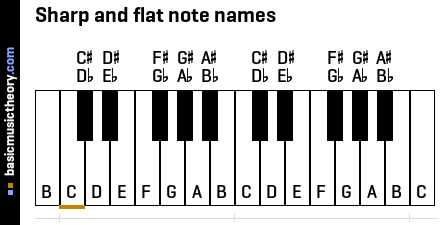
The audio files below play every note shown on the piano above, so middle C (marked with an orange line at the bottom) is the 2nd note heard.
| Bass Clef: | Midi | MP3 | Treble Clef: | Midi | MP3 |
2. A-double-flat note
Abb is a white key on the piano.
Another name for Abb is G, which has the same note pitch / sound, which means that the two note names are enharmonic to each other.
It is called double-flat because it is 2 half-tone(s) / semitone(s) down from the white note after which is is named - note A.
The next note up from Abb is Ab / G#.
Or put another way, Ab / G# is 1 half-tone / semitone higher than Abb.
The next note down from Abb is Gb / F#.
Or put another way, Gb / F# is 1 half-tone / semitone lower than Abb.
| Bass Clef: | Midi | MP3 | Treble Clef: | Midi | MP3 |
3. Note A-double-flat is found in which scales ?
| A-double-flat is the dominant of Dbb major scale (fifth note) |
| A-double-flat is the subdominant of Ebb major scale (fourth note) |
| A-double-flat is the tonic of Abb major scale (first note) |
| A-double-flat is the dominant of Dbb natural minor scale (fifth note) |
| A-double-flat is the subdominant of Ebb natural minor scale (fourth note) |
| A-double-flat is the mediant of Fb natural minor scale (third note) |
| A-double-flat is the tonic of Abb natural minor scale (first note) |
| A-double-flat is the subtonic of Bbb natural minor scale (seventh note) |
| A-double-flat is the submediant of Cb natural minor scale (sixth note) |
| A-double-flat is the dominant of Dbb harmonic minor scale (fifth note) |
| A-double-flat is the subdominant of Ebb harmonic minor scale (fourth note) |
| A-double-flat is the mediant of Fb harmonic minor scale (third note) |
| A-double-flat is the tonic of Abb harmonic minor scale (first note) |
| A-double-flat is the submediant of Cb harmonic minor scale (sixth note) |
| A-double-flat is the dominant of Dbb melodic minor scale (fifth note) |
| A-double-flat is the subdominant of Ebb melodic minor scale (fourth note) |
| A-double-flat is the mediant of Fb melodic minor scale (third note) |
| A-double-flat is the tonic of Abb melodic minor scale (first note) |
| Key | C | C# | Db | D | D# | Eb | E | E# | Fb | F | F# | Gb | G | G# | Ab | A | A# | Bb | B | B# | Cb |
|---|
| Related links | Note A-double-flat, Abb major scale |
|---|---|
| Minor scales | Abb natural minor scale, Abb harmonic minor scale, Abb melodic minor scale |
| More scales | Abb major scale |
| Intervals | Abb-1st, Abb-2nd, Abb-3rd, Abb-4th, Abb-5th, Abb-6th, Abb-7th, Abb-8th |
| Circle of 5ths | Learn the circle of fifths |
| Triad chords | Abb diminished, Abb minor, Abb major, Abb augmented, Abb suspended 2nd, Abb suspended 4th |
| 6th chords | Abb minor 6th, Abb major 6th |
| 7th chords | Abb dim 7, Abb half-dim7, Abb min 7, Abb min-maj 7, Abb dom 7, Abb maj 7, Abb aug 7, Abb aug-maj 7, Abb maj 7 sus2, Abb dom 7 sus4, Abb maj 7 sus4 |
| Cadences | Abb major perfect authentic, Abb major imperfect authentic, Abb major plagal, Abb major half, Abb major deceptive |